- Published on
Transliteration of Limbu Language
- Authors

- Name
- Astik Dahal
Transliteration of Limbu → Devanagari → Roman and Vice Versa
Natural Language Processing (NLP) for less-researched languages holds immense potential to preserve linguistic heritage while enabling new ways of interaction. This transliteration project for the Limbu language—a pioneering step towards linguistic inclusivity—aims to connect cultures and make underrepresented scripts accessible to the digital world. Let’s explore how we designed this system to tackle challenges, bridge gaps, and envision a brighter future.

Source: Radiant Treks, Limbu people on their traditional attire
Bridging Linguistic Gaps
Limbu (Limbu: ᤕᤠᤰᤌᤢᤱ ᤐᤠᤴ, yakthuṅ pan) is a Sino-Tibetan language spoken by the Limbu people of Nepal and Northeastern India (particularly West Bengal, Sikkim, Assam, and Nagaland) as well as expatriate communities in Bhutan. The Limbu refer to themselves as Yakthung, and their language as Yakthungpan. Yakthungpan has four main dialects: Phedape, Chhathare, Tambarkhole, and Panthare dialects. According to recent estimates, there are approximately 343,000 speakers of the language (Source: Wikipedia).
- Providing an inclusive digital platform for transliteration.
- Preserving linguistic heritage by making the Limbu script more accessible.
- Connecting cultures and enabling smoother communication between diverse linguistic communities.

yakthuṅ pan written in Limbu Script
Motive: Currently, there exists no transliteration service dedicated to the Limbu language, making it challenging for speakers to bridge their script with widely-used scripts like Devanagari and Roman. This project aims to fill that gap by:
This transliteration system for the Limbu language was designed with the following key modules:
- Core Logic :
- Dictionaries for Limbu→Roman, Roman→Limbu, Limbu→Devanagari, and Devanagari→Limbu mappings.
- A small offline dictionary for translating Devanagari month names to English.
- Round-trip testing to ensure fidelity across transliteration paths.
- Web Application:
- A Flask-based interface providing HTTP routes for user input and transliteration functionality.
- Front-End Interface:
- A single-page web application with dropdowns and test data for interactive demonstrations.
Problem Statement: Addressing Complex Challenges
By JFHJr - Own work, CC0, https://commons.wikimedia.org/w/index.php?curid=14037582
Transliterating the Limbu language presented unique technical challenges:
- Collision Handling: Ensuring no two Limbu characters map to the same Roman or Devanagari string, which could cause ambiguity in round-trip translations.
- Font Compatibility: Limbu script is not widely supported in web fonts, leading to rendering issues.
- Multi-Character Tokens: Accurately parsing and transliterating multi-character combinations, such as dependent vowels and subjoined letters.
- Linguistic Approximation: Mapping Limbu-specific linguistic constructs to approximate equivalents in Roman and Devanagari scripts.
By addressing these challenges with thoughtful design and testing, the project ensures seamless and accurate transliteration.
1. Limbu to Roman Transliteration

Dictionary Structure
The mappings for Limbu→Roman were broken into sub-dictionaries to maintain clarity:
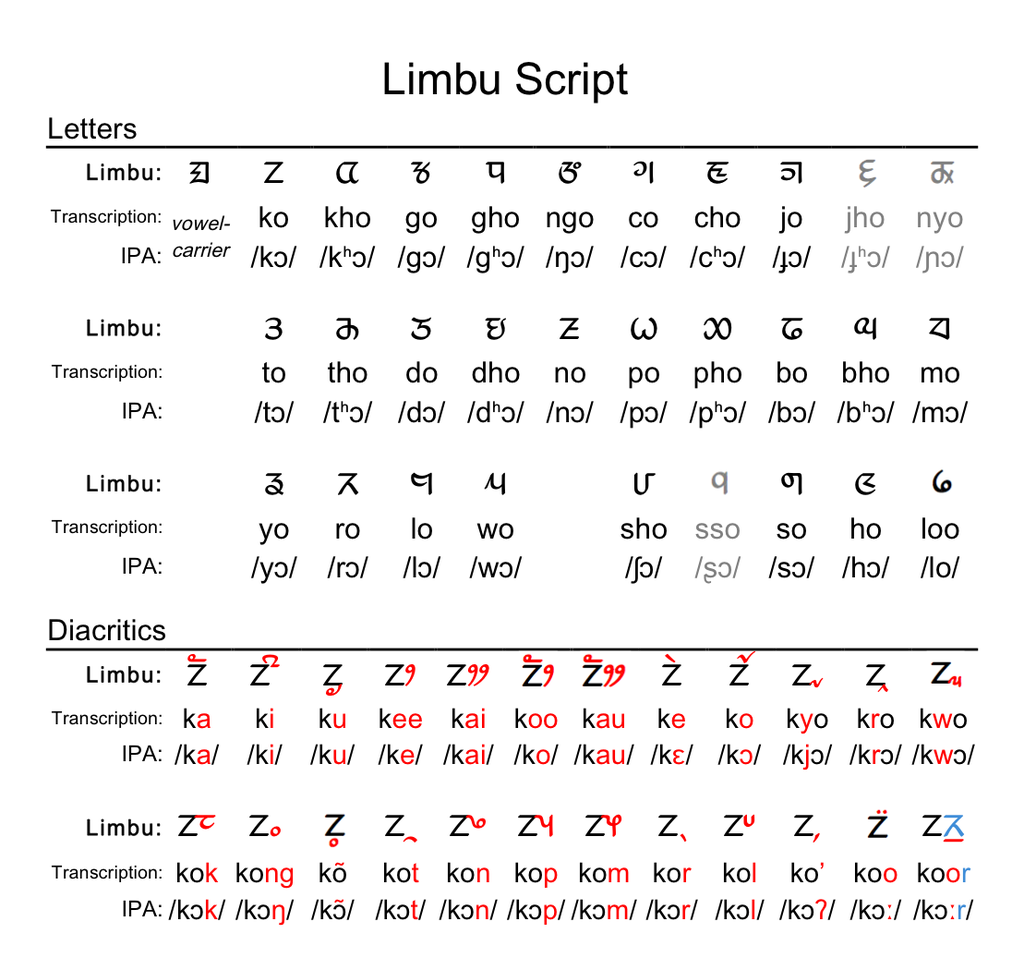
- Base Consonants (e.g., ᤁ = "ka")
- Dependent Vowels (e.g., ᤠ = "a")
- Subjoined Letters (e.g., ᤪ = "-rʲ")
- Final Small Consonants (e.g., ᤷ = "-r")
- Digits and Punctuation
By merging these sub-dictionaries, the system ensures modularity and simplicity in updating individual mappings.
Collision Handling
Transliteration must avoid mapping multiple Limbu codepoints to the same Roman string. For example:
- Subjoined RA (ᤪ) and Final R (ᤷ) naturally map to “-r.”
- To resolve this, unique tokens such as “-rʲ” and “-r” were assigned, ensuring round-trip fidelity.
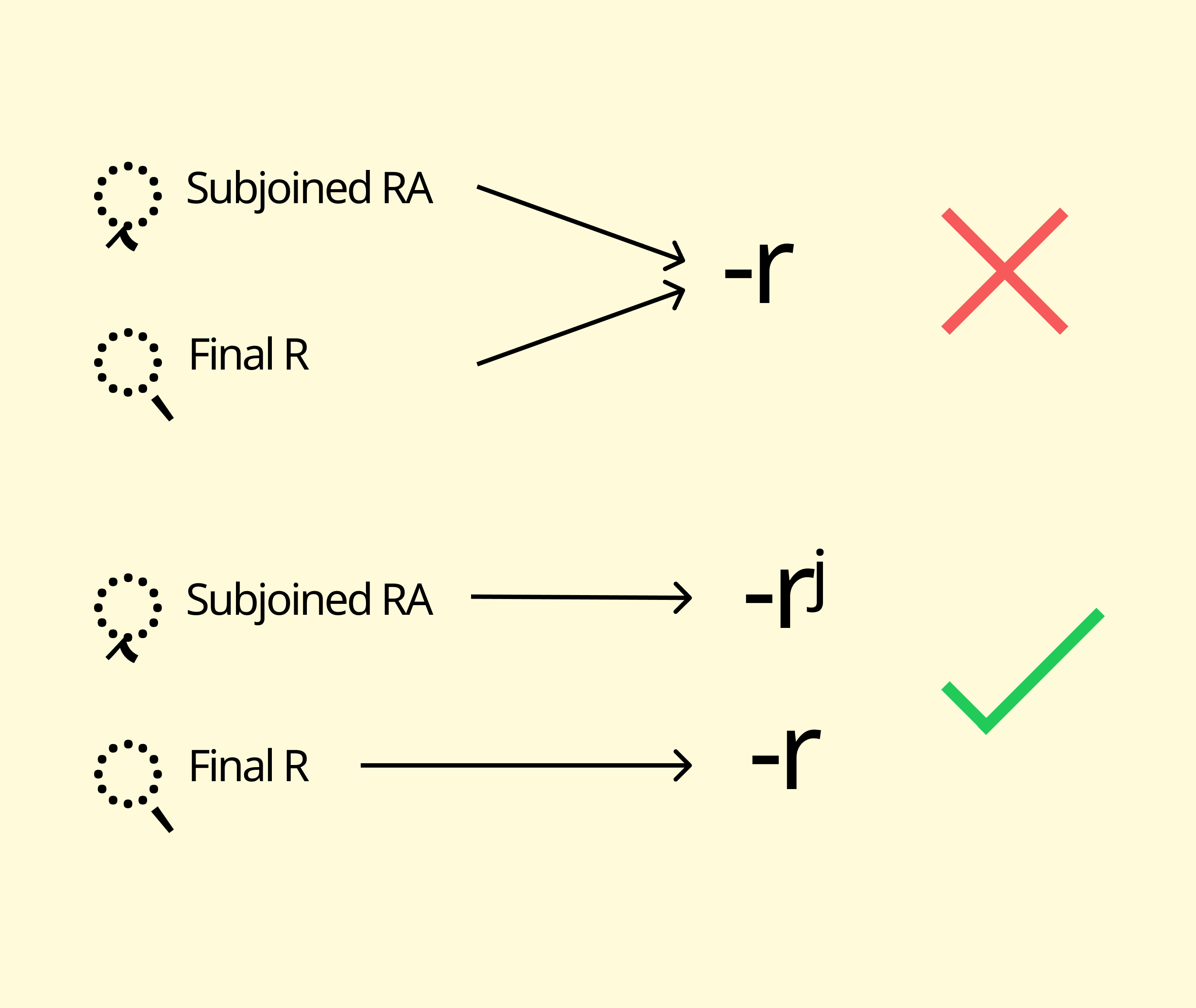
Fig: Collision Handling
Reverse Dictionary
For Roman→Limbu, the project utilized a reverse mapping algorithm that:
- Merges all Roman tokens into a dictionary.
- Sorts tokens by descending length to handle multi-letter combinations (e.g., "kha" over "k").
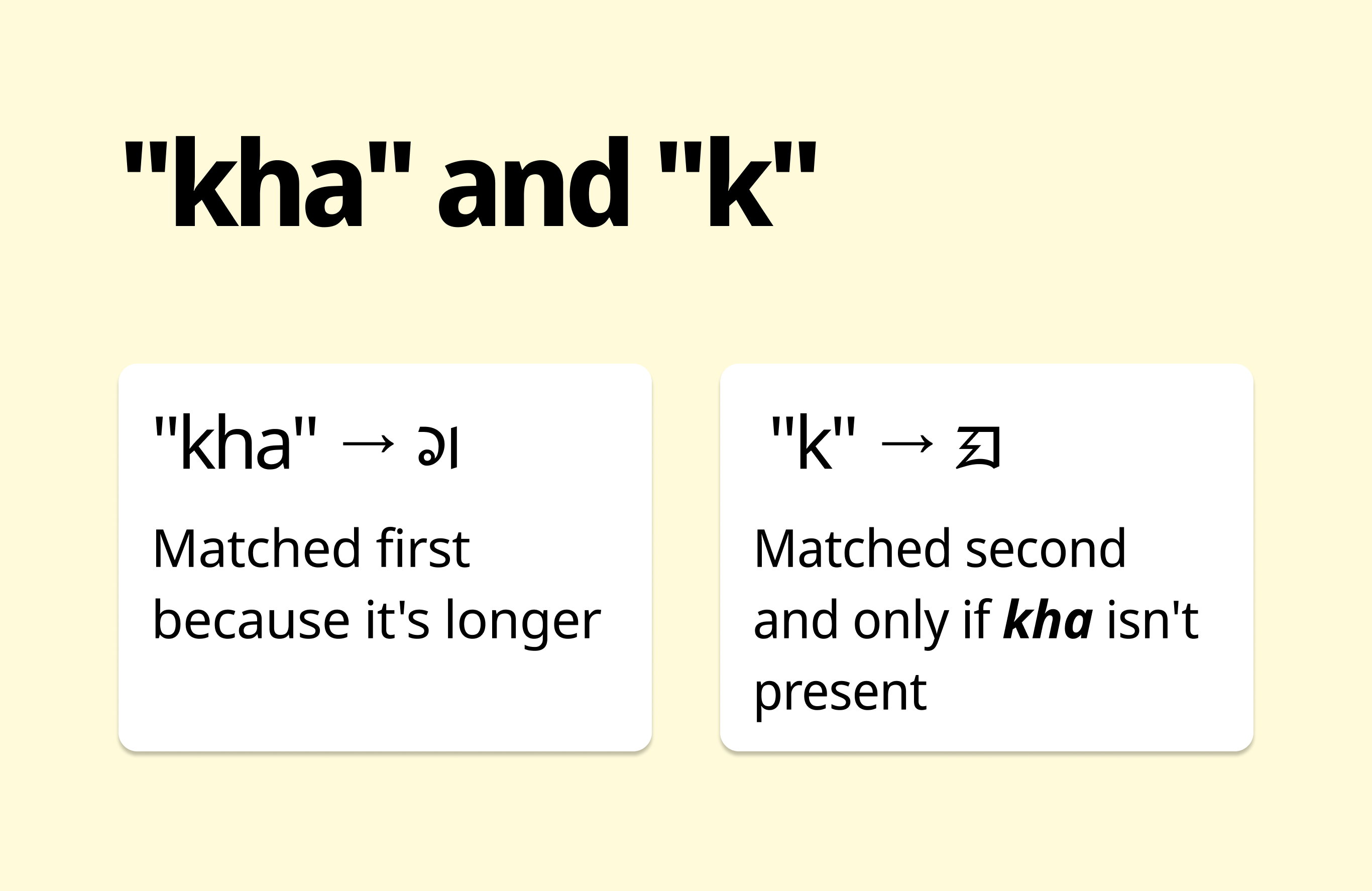
Fig: Reverse Dictionary and Sorting Tokens by Descending Length
2. Limbu to Devanagari Transliteration
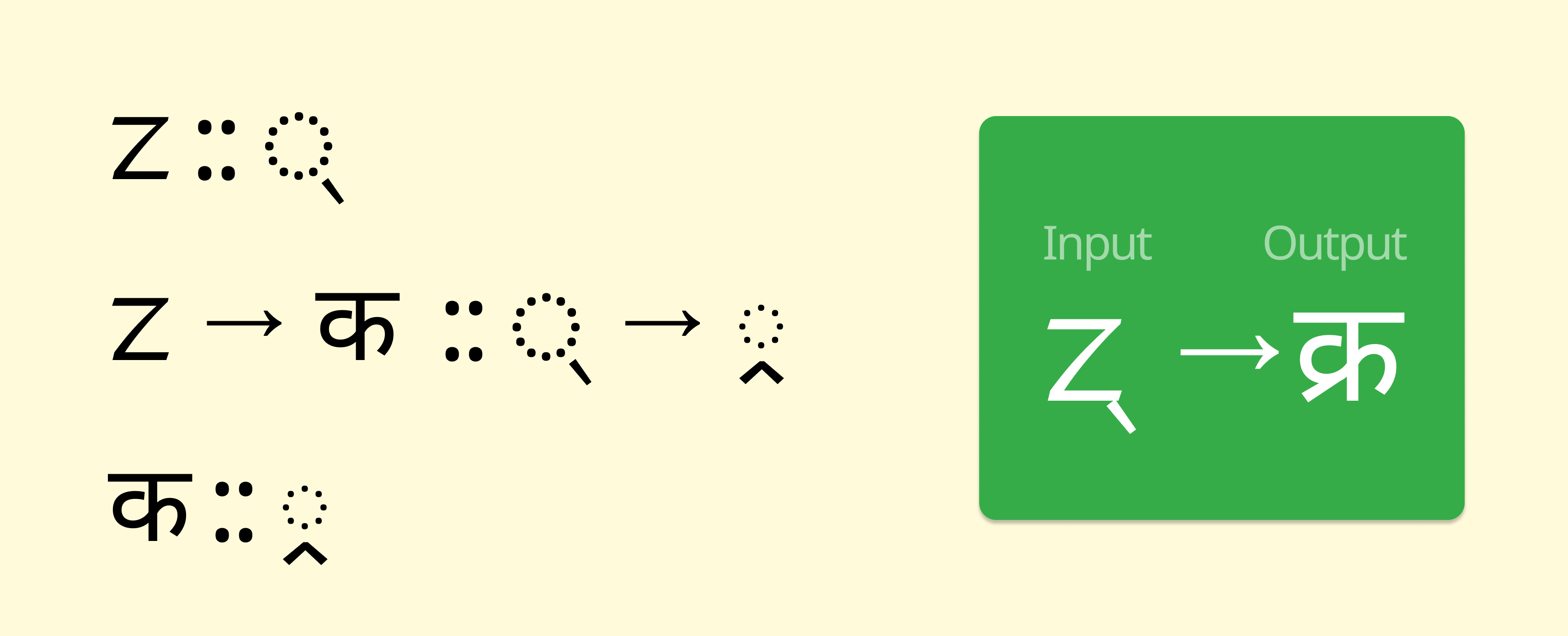
Mapping Limbu to Devanagari required careful approximations due to linguistic differences:
- Direct Mappings: Most base consonants (e.g., ᤁ = "क") were mapped directly.
- Approximations: Subjoined and final forms in Limbu were represented using halant forms in Devanagari (e.g., ᤷ = “्र”).
The system ensured bidirectional mappings for Devanagari→Limbu using similar dictionary merging and multi-character handling.
3. User Interface and Testing
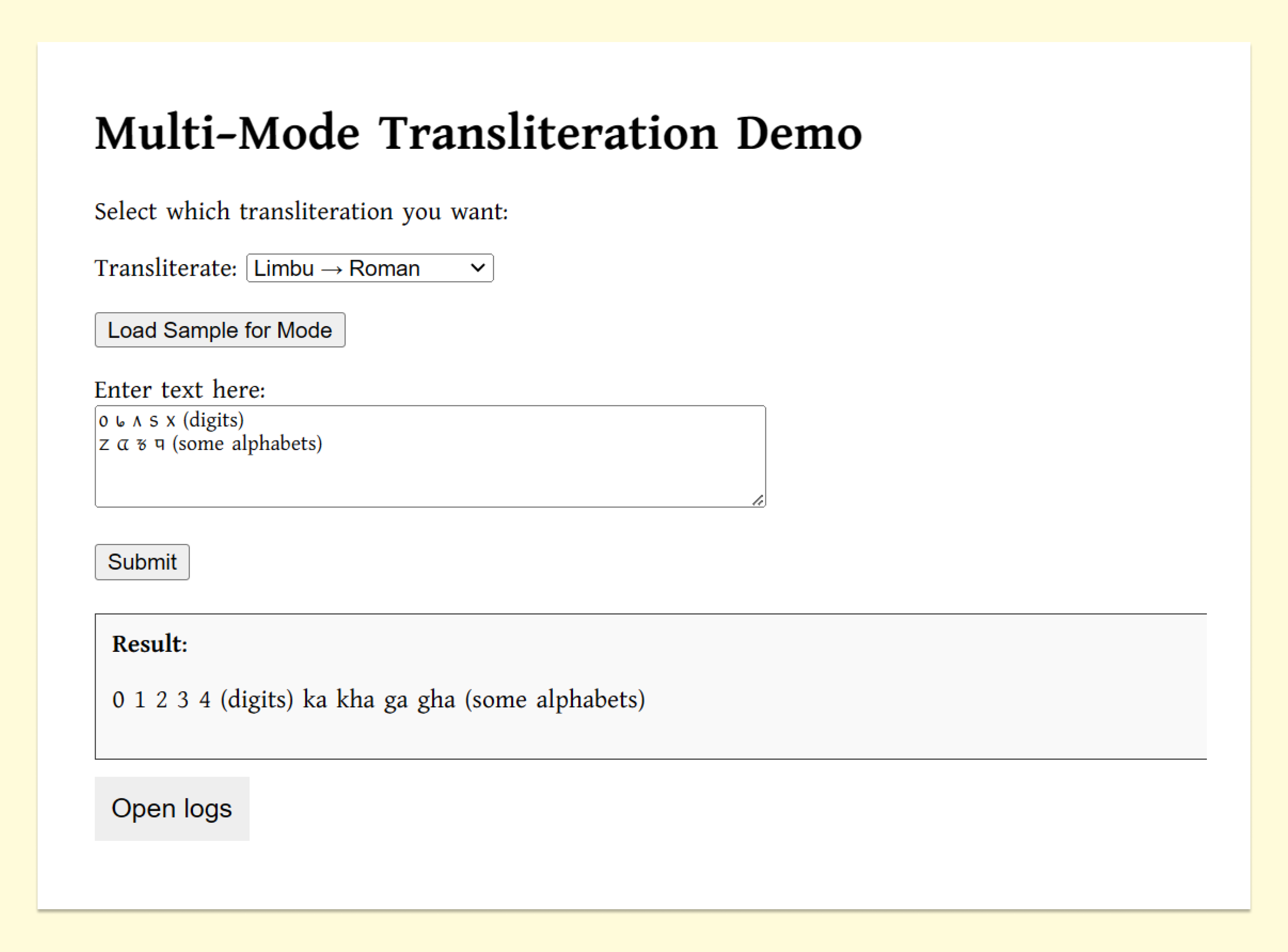
The UI is made very simple with minimal styling. The web interface (HTML) provided an intuitive experience with:
- Dropdown menus for selecting transliteration modes.
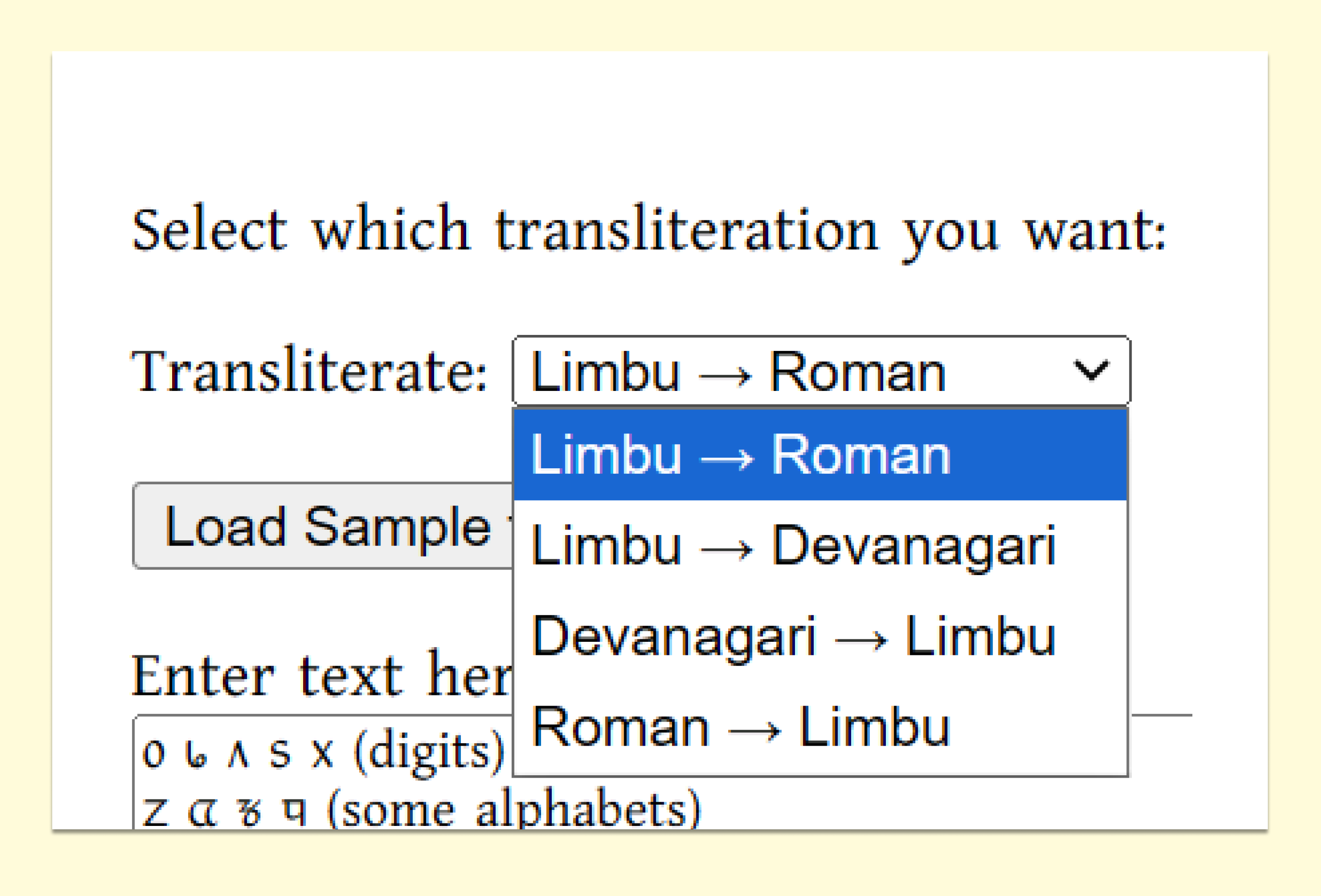
- Sample test data for quick demonstrations (e.g., Limbu digits).

- Accordion-based debug logs to trace transliteration steps in detail.

Round-Trip Testing
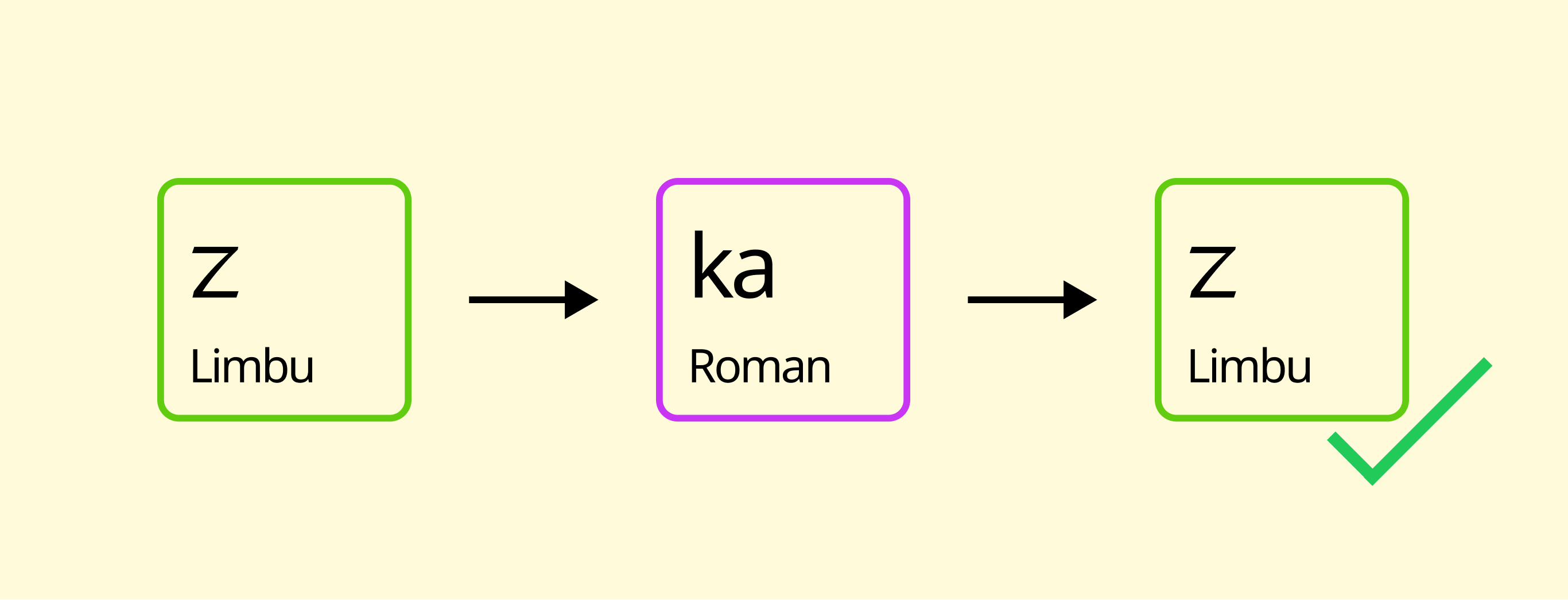
Fig: Round-Trip Testing
Automated tests validated every mapping through a cycle of transliteration and retranslation. For instance:
- A Limbu character is converted to Roman, then back to Limbu.
- Any mismatch signals a collision or mapping error, ensuring coverage of all codepoints in the Limbu block.
4. Addressing Font Compatibility
One significant challenge was the lack of Limbu script support. The solution:
- Self-host font such as Namdhinggo or Noto Sans Limbu or import from Google Fonts
- Ensuring correct glyph rendering across input/output text areas.
5. Future Works: Expanding Possibilities

Handwritten Limbu Scripts, Source: Brill
The next steps for this project include:
- OCR Integration: Developing Optical Character Recognition for Limbu scripts to process scanned documents and images.
- Computer Vision: Enhancing transliteration with context-aware recognition for handwritten or stylized scripts.
- Improved NLP Tools: Building smarter algorithms for linguistic analysis and better accuracy across transliteration tasks.
- Community Collaboration: Involving linguists, educators, and developers to refine the system and expand its use cases.
Conclusion: Bridging Cultures Through Technology
The Limbu Transliteration Project exemplifies how structured design and linguistic rigor can preserve and extend the usability of lesser-known scripts. By combining robust code architecture, thoughtful collision handling, and user-friendly interfaces, this system bridges linguistic barriers in an innovative and scalable manner.
Whether you are a linguist, developer, or language enthusiast, this project demonstrates how technology can safeguard cultural identity. With careful planning and inclusive design, we’ve taken a significant step forward in making the Limbu script accessible to the digital world. Let’s continue building tools that bring people and languages together.
Acknowledgements
This project draws inspiration and references from the detailed research available at Omniglot - Limbu Writing System. A special thanks to the creators of such valuable linguistic resources and to @sudiplimbu for personally helping me with this project.
The work is available on github. Feel free to check it.